Queries¶
Pony provides a very convenient way to query the database using the generator expression syntax. Pony allows programmers to work with objects which are stored in a database as if they were stored in memory, using native Python syntax. It makes development much easier.
For writing queries you can use Python generator expressions or lambdas.
Using Python generator expressions¶
Pony allows to use generator expressions as a very natural way of writing database queries. Pony provides select() function which accepts Python generator, translates it to SQL and returns objects from the database. The process of the translation is described in this StackOverflow question.
Here is an example of a query:
query = select(c for c in Customer
if sum(o.total_price for o in c.orders) > 1000)
or, with attribute lifting:
query = select(c for c in Customer
if sum(c.orders.total_price) > 1000)
You can apply filter() function to query
query2 = query.filter(lambda person: person.age > 18)
Also you can make new query based on another query:
query3 = select(customer.name for customer in query2
if customer.country == 'Canada')
select() function returns an instance of a Query class, and you can then call the Query object methods for getting the result, for example:
customer_name = query3.first()
From query you can return entity, attribute or tuple of arbitrary expressions
select((c, sum(c.orders.total_price))
for c in Customer if sum(c.orders.total_price) > 1000)
Using lambda functions¶
Instead of using a generator, you can write queries using the lambda function:
Customer.select(lambda c: sum(c.orders.price) > 1000)
From the point of the translation the query into SQL there is no difference, if you use a generator or a lambda. The only difference is that using the lambda you can only return entity instances - there is no way to return a list of specific entity attributes or a list of tuples.
Pony ORM functions used to query the database¶
See the Queries and functions part of the API Reference for details.
Pony query examples¶
For demonstrating Pony queries let’s use the example from the Pony ORM distribution. You can try these queries yourself in the interactive mode and see the generated SQL. For this purpose import the example module this way:
>>> from pony.orm.examples.estore import *
This module offers a simplified data model of a eCommerce online store. Here is the ER Diagram of the data model:
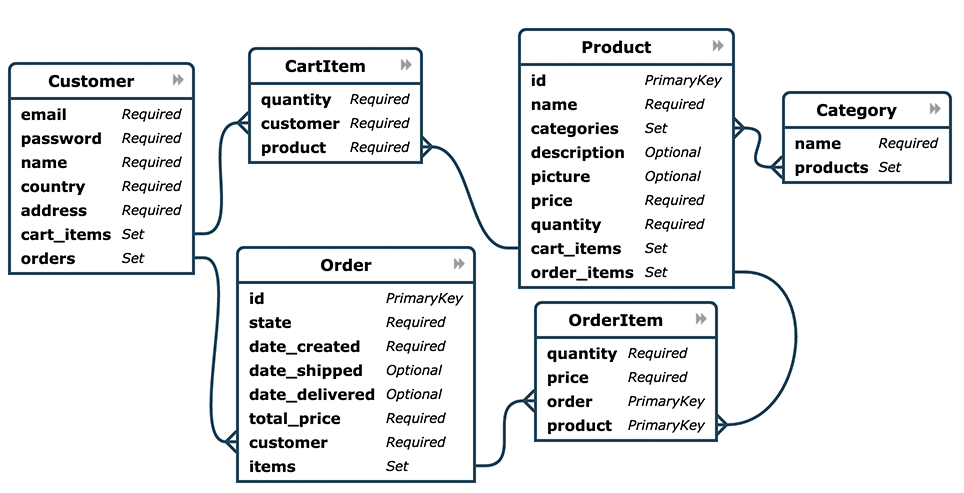
Here are the entity definitions:
from decimal import Decimal
from datetime import datetime
from pony.converting import str2datetime
from pony.orm import *
db = Database()
class Customer(db.Entity):
email = Required(str, unique=True)
password = Required(str)
name = Required(str)
country = Required(str)
address = Required(str)
cart_items = Set('CartItem')
orders = Set('Order')
class Product(db.Entity):
id = PrimaryKey(int, auto=True)
name = Required(str)
categories = Set('Category')
description = Optional(str)
picture = Optional(buffer)
price = Required(Decimal)
quantity = Required(int)
cart_items = Set('CartItem')
order_items = Set('OrderItem')
class CartItem(db.Entity):
quantity = Required(int)
customer = Required(Customer)
product = Required(Product)
class OrderItem(db.Entity):
quantity = Required(int)
price = Required(Decimal)
order = Required('Order')
product = Required(Product)
PrimaryKey(order, product)
class Order(db.Entity):
id = PrimaryKey(int, auto=True)
state = Required(str)
date_created = Required(datetime)
date_shipped = Optional(datetime)
date_delivered = Optional(datetime)
total_price = Required(Decimal)
customer = Required(Customer)
items = Set(OrderItem)
class Category(db.Entity):
name = Required(str, unique=True)
products = Set(Product)
set_sql_debug(True)
db.bind('sqlite', 'estore.sqlite', create_db=True)
db.generate_mapping(create_tables=True)
When you import this example, it will create the SQLite database in the file ‘estore.sqlite’ and fill it with some test data. Below you can see some query examples:
# All USA customers
Customer.select(lambda c: c.country == 'USA')
# The number of customers for each country
select((c.country, count(c)) for c in Customer)
# Max product price
max(p.price for p in Product)
# Max SSD price
max(p.price for p in Product
for cat in p.categories if cat.name == 'Solid State Drives')
# Three most expensive products
Product.select().order_by(desc(Product.price))[:3]
# Out of stock products
Product.select(lambda p: p.quantity == 0)
# Most popular product
Product.select().order_by(lambda p: desc(sum(p.order_items.quantity))).first()
# Products that have never been ordered
Product.select(lambda p: not p.order_items)
# Customers who made several orders
Customer.select(lambda c: count(c.orders) > 1)
# Three most valuable customers
Customer.select().order_by(lambda c: desc(sum(c.orders.total_price)))[:3]
# Customers whose orders were shipped
Customer.select(lambda c: SHIPPED in c.orders.state)
# Customers with no orders
Customer.select(lambda c: not c.orders)
# The same query with the LEFT JOIN instead of NOT EXISTS
left_join(c for c in Customer for o in c.orders if o is None)
# Customers which ordered several different tablets
select(c for c in Customer
for p in c.orders.items.product
if 'Tablets' in p.categories.name and count(p) > 1)
You can find more queries in the pony.orm.examples.estore module.
Query object methods¶
See the Query result part of the API Reference for details.
Using date and time in queries¶
You can perform arithmetic operations with the datetime and timedelta in queries.
If the expression can be calculated in Python, Pony will pass the result of the calculation as a parameter into the query:
select(o for o in Order if o.date_created >= datetime.now() - timedelta(days=3))[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE "o"."date_created" >= ?
If the operation needs to be performed with the attribute, we cannot calculate it beforehand. That is why such expression will be translated into SQL:
select(o for o in Order if o.date_created + timedelta(days=3) >= datetime.now())[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE datetime("o"."date_created", '+3 days') >= ?
The SQL generated by Pony will vary depending on the database. Above is the example for SQLite. Here is the same query, translated into PostgreSQL:
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "order" "o"
WHERE ("o"."date_created" + INTERVAL '72:0:0' DAY TO SECOND) >= %(p1)s
If you need to use a SQL function, you can use the raw_sql() function in order to include this SQL fragment:
select(m for m in DBVoteMessage if m.date >= raw_sql("NOW() - '1 minute'::INTERVAL"))
With Pony you can use the datetime attributes, such as month, hour, etc. Depending on the database, it will be translated into different SQL, which extracts the value for this attribute. In this example we get the month attribute:
select(o for o in Order if o.date_created.month == 12)
Here is the result of the translation for SQLite:
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE cast(substr("o"."date_created", 6, 2) as integer) = 12
And for PostgreSQL:
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "order" "o"
WHERE EXTRACT(MONTH FROM "o"."date_created") = 12
Automatic DISTINCT¶
Pony tries to avoid duplicates in a query result by automatically adding the DISTINCT SQL keyword where it is necessary, because useful queries with duplicates are very rare. When someone wants to retrieve objects with a specific criteria, they typically don’t expect that the same object will be returned more than once. Also, avoiding duplicates makes the query result more predictable: you don’t need to filter duplicates out of a query result.
Pony adds the DISCTINCT keyword only when there could be potential duplicates. Let’s consider a couple of examples.
Retrieving objects with a criteria:
Person.select(lambda p: p.age > 20 and p.name == 'John')
In this example, the query doesn’t return duplicates, because the result contains the primary key column of a Person. Since duplicates are not possible here, there is no need in the DISTINCT keyword, and Pony doesn’t add it:
SELECT "p"."id", "p"."name", "p"."age"
FROM "Person" "p"
WHERE "p"."age" > 20
AND "p"."name" = 'John'
Retrieving object attributes:
select(p.name for p in Person)
The result of this query returns not objects, but its attribute. This query result can contain duplicates, so Pony will add DISTINCT to this query:
SELECT DISTINCT "p"."name"
FROM "Person" "p"
The result of a such query typically used for a dropdown list, where duplicates are not expected. It is not easy to come up with a real use-case when you want to have duplicates here.
If you need to count persons with the same name, you’d better use an aggregate query:
select((p.name, count(p)) for p in Person)
But if it is absolutely necessary to get all person’s names, including duplicates, you can do so by using the Query.without_distinct() method:
select(p.name for p in Person).without_distinct()
Retrieving objects using joins:
select(p for p in Person for c in p.cars if c.make in ("Toyota", "Honda"))
This query can contain duplicates, so Pony eliminates them using DISTINCT:
SELECT DISTINCT "p"."id", "p"."name", "p"."age"
FROM "Person" "p", "Car" "c"
WHERE "c"."make" IN ('Toyota', 'Honda')
AND "p"."id" = "c"."owner"
Without using DISTINCT the duplicates are possible, because the query uses two tables (Person and Car), but only one table is used in the SELECT section. The query above returns only persons (and not their cars), and therefore it is typically not desirable to get the same person in the result more than once. We believe that without duplicates the result looks more intuitive.
But if for some reason you don’t need to exclude duplicates, you always can add without_distinct() to the query:
select(p for p in Person for c in p.cars
if c.make in ("Toyota", "Honda")).without_distinct()
The user probably would like to see the Person objects duplicates if the query result contains cars owned by each person. In this case the Pony query would be different:
select((p, c) for p in Person for c in p.cars if c.make in ("Toyota", "Honda"))
And in this case Pony will not add the DISTINCT keyword to SQL query.
To summarize:
The principle “all queries do not return duplicates by default” is easy to understand and doesn’t lead to surprises.
Such behavior is what most users want in most cases.
Pony doesn’t add DISTINCT when a query is not supposed to have duplicates.
The query method
without_distinct()can be used for forcing Pony do not eliminate duplicates.
Functions which can be used inside a query¶
Here is the list of functions that can be used inside a generator query:
abs()
Examples:
select(avg(c.orders.total_price) for c in Customer)
SELECT AVG("order-1"."total_price")
FROM "Customer" "c"
LEFT JOIN "Order" "order-1"
ON "c"."id" = "order-1"."customer"
select(o for o in Order if o.customer in
select(c for c in Customer if c.name.startswith('A')))[:]
SELECT "o"."id", "o"."state", "o"."date_created", "o"."date_shipped",
"o"."date_delivered", "o"."total_price", "o"."customer"
FROM "Order" "o"
WHERE "o"."customer" IN (
SELECT "c"."id"
FROM "Customer" "c"
WHERE "c"."name" LIKE 'A%'
)
Using getattr()¶
getattr() is a built-in Python function, that can be used for getting the attribute value.
Example:
attr_name = 'name'
param_value = 'John'
select(c for c in Customer if getattr(c, attr_name) == param_value)
Using raw SQL¶
Pony allows using raw SQL in your queries. There are two options on how you can use raw SQL:
Use the
raw_sql()function in order to write only a part of a generator or lambda query using raw SQL.Write a complete SQL query using the
Entity.select_by_sql()orEntity.get_by_sql()methods.
Using the raw_sql() function¶
Let’s explore examples of using the raw_sql() function. Here is the schema and initial data that we’ll use for our examples:
from datetime import date
from pony.orm import *
db = Database('sqlite', ':memory:')
class Person(db.Entity):
id = PrimaryKey(int)
name = Required(str)
age = Required(int)
dob = Required(date)
db.generate_mapping(create_tables=True)
with db_session:
Person(id=1, name='John', age=30, dob=date(1986, 1, 1))
Person(id=2, name='Mike', age=32, dob=date(1984, 5, 20))
Person(id=3, name='Mary', age=20, dob=date(1996, 2, 15))
The raw_sql() result can be treated as a logical expression:
select(p for p in Person if raw_sql('abs("p"."age") > 25'))
The raw_sql() result can be used for a comparison:
q = Person.select(lambda x: raw_sql('abs("x"."age")') > 25)
print(q.get_sql())
SELECT "x"."id", "x"."name", "x"."age", "x"."dob"
FROM "Person" "x"
WHERE abs("x"."age") > 25
Also, in the example above we use raw_sql() in a lambda query and print out the resulting SQL. As you can see the raw SQL part becomes a part of the whole query.
The raw_sql() can accept $parameters:
x = 25
select(p for p in Person if raw_sql('abs("p"."age") > $x'))
You can change the content of the raw_sql() function dynamically and still use parameters inside:
x = 1
s = 'p.id > $x'
select(p for p in Person if raw_sql(s))
Another way of using dynamic raw SQL content:
x = 1
cond = raw_sql('p.id > $x')
select(p for p in Person if cond)
You can use various types inside the raw SQL query:
x = date(1990, 1, 1)
select(p for p in Person if raw_sql('p.dob < $x'))
Parameters inside the raw SQL part can be combined:
x = 10
y = 15
select(p for p in Person if raw_sql('p.age > $(x + y)'))
You can even call Python functions inside:
select(p for p in Person if raw_sql('p.dob < $date.today()'))
The raw_sql() function can be used not only in the condition part, but also in the part which returns the result of the query:
names = select(raw_sql('UPPER(p.name)') for p in Person)[:]
print(names)
['JOHN', 'MIKE', 'MARY']
But when you return data using the raw_sql() function, you might need to specify the type of the result, because Pony has no idea on what the result type is:
dates = select(raw_sql('(p.dob)') for p in Person)[:]
print(dates)
['1985-01-01', '1983-05-20', '1995-02-15']
If you want to get the result as a list of dates, you need to specify the result_type:
dates = select(raw_sql('(p.dob)', result_type=date) for p in Person)[:]
print(dates)
[datetime.date(1986, 1, 1), datetime.date(1984, 5, 20), datetime.date(1996, 2, 15)]
The raw_sql() function can be used in a Query.filter() too:
x = 25
select(p for p in Person).filter(lambda p: p.age > raw_sql('$x'))
It can be used inside the Query.filter() without lambda. In this case you have to use the first letter of entity name in lower case as the alias:
x = 25
Person.select().filter(raw_sql('p.age > $x'))
You can use several raw_sql() expressions in a single query:
x = '123'
y = 'John'
Person.select(lambda p: raw_sql("UPPER(p.name) || $x")
== raw_sql("UPPER($y || '123')"))
The same parameter names can be used several times with different types and values:
x = 10
y = 31
q = select(p for p in Person if p.age > x and p.age < raw_sql('$y'))
x = date(1980, 1, 1)
y = 'j'
q = q.filter(lambda p: p.dob > x and p.name.startswith(raw_sql('UPPER($y)')))
persons = q[:]
You can use raw_sql() in Query.order_by() section:
x = 9
Person.select().order_by(lambda p: raw_sql('SUBSTR(p.dob, $x)'))
Or without lambda, if you use the same alias, that you used in previous filters. In this case we use the default alias - the first letter of the entity name:
x = 9
Person.select().order_by(raw_sql('SUBSTR(p.dob, $x)'))
Using the select_by_sql() and get_by_sql() methods¶
Although Pony can translate almost any condition written in Python to SQL, sometimes the need arises to use raw SQL, for example - in order to call a stored procedure or to use a dialect feature of a specific database system. In this case, Pony allows the user to write a query in a raw SQL, by placing it inside the function Entity.select_by_sql() or Entity.get_by_sql() as a string:
Product.select_by_sql("SELECT * FROM Products")
Unlike the method Entity.select(), the method Entity.select_by_sql() does not return the Query object, but a list of entity instances.
Parameters are passed using the following syntax: “$name_variable” or “$(expression in Python)”. For example:
x = 1000
y = 500
Product.select_by_sql("SELECT * FROM Product WHERE price > $x OR price = $(y * 2)")
When Pony encounters a parameter within a raw SQL query, it gets the variable value from the current frame (from globals and locals) or from the dictionaries which can be passed as parameters:
Product.select_by_sql("SELECT * FROM Product WHERE price > $x OR price = $(y * 2)",
globals={'x': 100}, locals={'y': 200})
Variables and more complex expressions specified after the $ sign, will be automatically calculated and transferred into the query as parameters, which makes SQL-injection impossible. Pony automatically replaces $x in the query string with “?”, “%S” or with other paramstyle, used in your database.
If you need to use the $ sign in the query (for example, in the name of a system table), you have to write two $ signs in succession: $$.